Avant de commencer....
Ce tutoriel est de niveau avancé : pour pouvoir le suivre, vous devez avoir les prérequis suivants :
- être familier avec les commandes unix
- Connaître la programmation : de préférence fortran, éventuellement C
- Savoir écrire un fichier make, compiler un programme, l’exécuter en utilisant le système de queue de Calmip
Afin d’exécuter ce tutoriel, il vous faut installer sur votre compte sur eos/olympe ce code de tests. Nous utiliserons quelques outils simple d’Unix, et notamment l’outil placement développé à Calmip. Mais nous utiliserons aussi les outils d’Intel : compilateur fortran et environnement de développement
Avant toute chose vous devez donc initialiser l’environnement de développement d’intel, de préférence le plus récent.
module purge module load intel/18.2
Etude du code
Allez dans le répertoire 01-vectorisation_boucle et éditez le fichier vect.f90. Les fonctions importantes sont :
initqui initialise 5 vecteurs(1) de flottants appelésa,b,c,d,e. La dimension est de 625 millions de cellules, soit625 * 8 * 5 = 25 Goalloués dynamiquement.test0qui va calculera = b * c + d * e
Éditez maintenant le fichier Makefile :
- Vers la ligne 16, une variable vous permet d’activer ou désactiver la vectorisation voir ici
- Compilez et exécutez avec et sans la vectorisation. Le fichier make appelle deux fois le compilateur : une fois pour générer l’exécutable, et une autre fois pour générer le code assembleur et le copier dans un fichier lisible.
make clean make sbatch sbatch.slurm
Vous pouvez constater que la vectorisation est bien activée (instructions vXXX) :
diff vect-no-vect.cod vect-xAVX.code
... Et pourtant ça ne va pas plus vite ! (voir les fichiers out.txt*). Damned ! Le processeur est-il en panne ? Même pas ! Mais avant de comprendre ce qui se passe, étudions la notion de bande passante mémoire.
Observer la mémoire avec des outils simples
Allez dans le répertoire 02-bande_passante. Éditez le Makefile et vers la ligne 12 supprimez openmp (pour que le programme n’aille pas trop vite car on ne verrait rien), et compilez :
make
Lancez le programme sur un nœud, connectez-vous sur le nœud et appelez la commande top :
sbatch batch.slurm ssh olympecompxxx top
Observez les colonnes VIRT et RES : VIRT est dès le début du job à 24.4g, alors que RES augmente progressivement.
VIRTmontre la réservation en termes de mémoire virtuelle, celle-ci est fixée dès l’appel àallocate(ligne 15 du programme fortran).RESmontre la mémoire résidente, c’est-à -dire réellement allouée. La mémoire n’est allouée qu’en cas de besoin, au fur et à mesure que les vecteurs se remplissent (fonctioninit).
Recompilez avec openmp (fichier Makefile), et éditez batch.slurm pour mettre la variable MODE sur scatter. Cette variable est utilisée avec la commande placement.Exécutez la ligne bash suivante :
sbatch batch.slurm; while(true); do placement --checkme --threads --mem; sleep 1; done
Vous devez observer un affichage qui ressemble à cela :
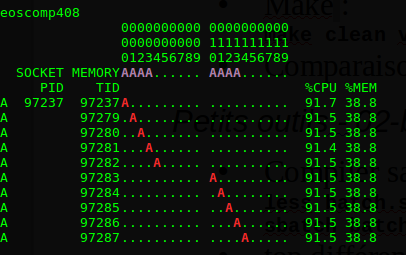
On voit aisément que :
- Le programme utilise 10 "threads" (lettres A en rouge) réparties sur chaque socket, donc 5 cœurs sont utilisés sur chaque socket
- La mémoire est répartie également sur les deux sockets (lettre A en violet), et chaque thread accède à la mémoire qui se trouve connectée à son processeur (socket).
Éditez maintenant batch.slurm pour mettre la variable MODE sur compact. Exécutez la même commande que précédemment. Cette fois vous devez observer un affichage qui ressemble à cela :
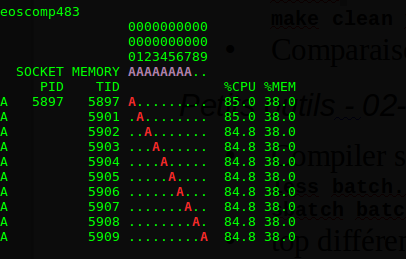
On voit aisément que :
- Le programme utilise toujours 10 "threads" (lettres A en rouge) mais cette fois elles tournent sur les 10 cœurs du premier socket.
- La mémoire est allouée sur le même socket (lettre A en violet), donc là encore chaque thread accède à la mémoire sur le bon socket. Par contre, par rapport au cas précédent, la bande passante mémoire sera deux fois plus faible. En effet, on peut voir dans les fichiers de sortie qu’on va bien moins vite en placement compact qu’en scatter.
Enfin, éditez à nouveau batch.slurm pour repasser en SCATTER, et éditez également le fichier vect.f90 : aux alentours de la ligne 54, commentez l’appel openmp, afin de ne pas utiliser openmp dans la fonction init. recompilez, exécutez comme précédemment, et cette fois voici ce que vous obtenez :
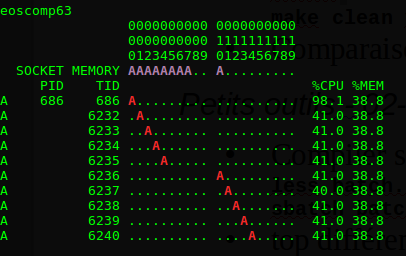
On voit cette fois que les threads se distribuent sur les deux sockets, mais la mémoire, ayant été initialisée de manière séquentielle par la thread 0, n’est allouée que sur le premier socket. Il s’ensuit que la moitié des threads devra accéder à la mémoire de manière plus lente, donc la bande passante ne sera pas optimale.
La conclusion est que pour avoir de bonnes performances il est important d’initialiser les données en utilisant openmp .
Des outils simples permettent de recueillir pas mal d’informations sur votre code. Mais dans l’environnement de développement, nous avons aussi des outils de développement plus sophistiqués qui peuvent aussi être mis à contribution...
Utilisation de vtune pour vérifier l’équilibrage de charge
Allez dans le répertoire 02-bande_passante. Compilez avec openmp, assurez-vous qu’openmp est bien utilisé dans la procédure d’initialisation (cf. ci-dessus), et éditez batch.slurm afin de décommenter les lignes concernant vtune (vers la ligne14).
Appelez la commande sbatch puis observez le résultat de la mesure avec :
amplxe-gui r000hs
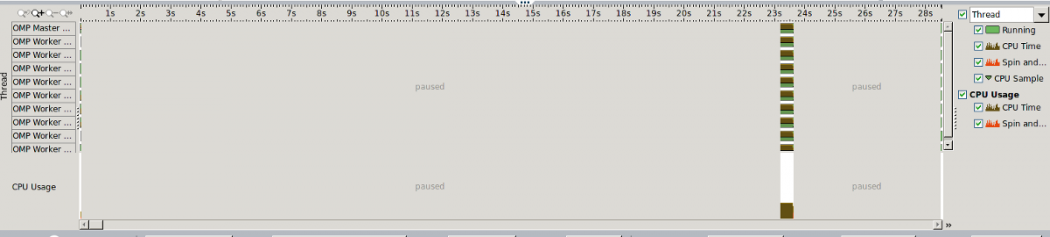
Cliquez sur le bouton Bottom-up, et cochez la case CPU Sample (en bas à droite de l’écran). Vous observez en bas de l’écran un graphique ressemblant à celui-ci :

Ce graphique montre ce qui se passe avec votre programme et ses différentes threads. Vous pouvez voir dans quelle fonction on se trouve en promenant la souris sur le graphique. Et en faisant cela, vous verrez que votre programme passe l’essentiel de son temps dans la routine d’initialisation, et moins de une seconde dans la routine test0, la seule qui nous intéresse vraiment ! Cette situation est un peu frustrante, surtout que dans un cas réel il n’est pas toujours très simple de trouver la fonction qui nous intéresse vraiment. Nous pouvons y remédier en instrumentalisant notre code :
Ouvrez le programme fortran et décommentez les lignes marquées call itt_XXX : ces lignes appellent des fonctions liées à vtune, et vont permettre d’activer ou désactiver la prise de mesure par l’outil vtune.
Puis recompilez et relancez le script batch comme précédemment, relancez amplxe-gui, vous avez ce graphique :
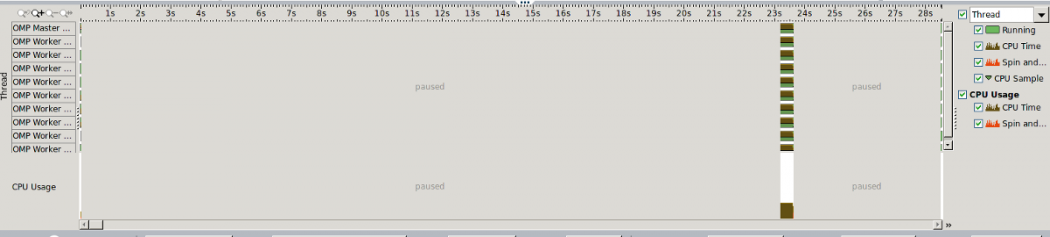
On ne voit pas grand-chose de plus que précédemment, mais cette fois on identifie sans ambiguïté la zone d’intérêt, et il est simple de zoomer dessus. Les petits triangles verts correspondent aux "points de mesure" de l’outil :
La couleur brun foncé correspond aux moments où du travail utile est effectué, la couleur orange correspond aux moments où les threads ne font rien d’autre qu’attendre. On peut ainsi visualiser de manière très simple l’équilibrage de charge entre les threads, en l’occurrence il est plutôt bon. (quelques millisecondes d’attente).
Maintenant, supprimons comme précédemment l’utilisation d’openmp dans la fonction init, et voyons ce qui se passe. Il suffit de commenter une ligne (vers la ligne 54 de vect.f90), recompiler, exécuter le sbatch (cela dure bien plus longtemps car l’initialisation n’est plus parallélisée) puis amplxe-gui, et nous avons le graphique suivant, plutôt éloquent en termes d’équilibrage de charge. Les threads les plus rapides (celles qui ont les données du bon côté de la mémoire) attendent les retardataires plus de 150 ms, autant dire une éternité :
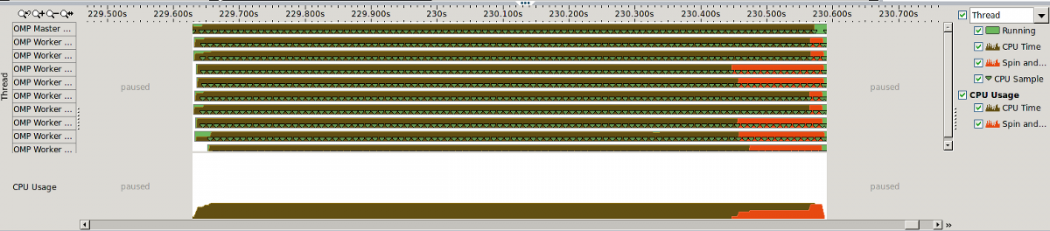
Il est clair à ce stade que notre routine test0 est entièrement contrôlée par la bande passante mémoire. Nous pouvons utiliser les processeurs les plus puissants du monde et vectoriser comme des fous, cela ne changera pas. Le paragraphe suivant montre un moyen de vérifier, boucle par boucle, si nous sommes bornés par la mémoire, ou au contraire s’il y a des marges d’amélioration.
Le roofline sans peine
Nous allons utiliser un autre outil de développement d’intel : Advisor, pour générer de manière très simple le graphique décrit ici de manière théorique.
Allez dans le répertoire 03-roofline_model et ouvrez le fichier vect.f90 : vous verrez qu’en plus de la fonction test0, vous trouverez d’autres fonctions test1, test2 etc. ; chacune de ces fonctions a une intensité arithmétique différente, comme expliqué ici (ce sont les mêmes boucles).
Lancez tout d’abord la commande :
advixe-gui
Cliquez sur le lien New project, donnez un nom au projet, et indiquez dans le formulaire qui s’ouvre le nom de l’exécutable (vect). Une fenêtre s’ouvre alors, recherchez la mention à gauche Run Roofline et cliquez sur l’icône juste à droite, elle est marquée lors du survol de la souris Get Command Line .
Un popup s’ouvre alors avec une horrible commande : cliquez sur COPY, fermez advisor puis éditez le fichier batch.slurm et collez l’horrible commande à la place de la mention COMMANDE PROPOSEE PAR ADVIZER
Exécutez sbatch et ouvrez à nouveau Advisor. Cliquez sur votre projet puis sur Open my results. Cela ouvre une fenêtre, cliquez alors sur Survey & Roofline : vous pourrez alterner entre le diagramme ROOFLINE et l’écran SURVEY.
Dans l’écran ROOFLINE cliquez sur Use Single-Threaded Roofs, vous aurez le beau toit suivant :
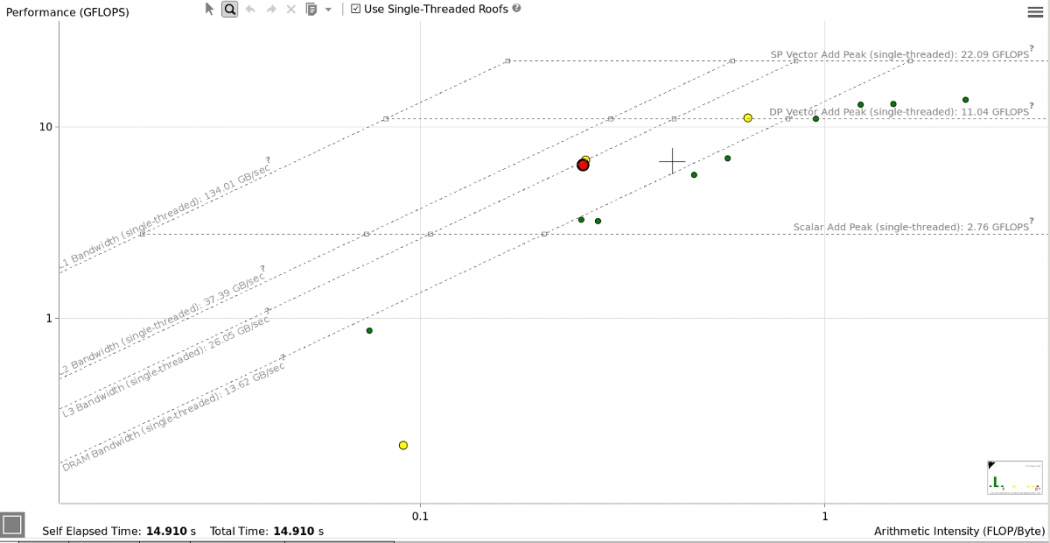
Ce graphique montre que les différentes routines (passez la souris sur les points verts pour voir à quelle routine chacun correspond) sont toutes, à des degrés divers, bornées par la mémoire.
(1) Nous appelons vecteur un tableau à 1 dimension