Vectorisation d’un calcul
Dans cet article on s’intéresse à la notion de vectorisation, sa mise en œuvre sur le système de calcul et son intérêt en termes de temps de calcul.
Le principe du calcul vectoriel repose sur le traitement simultané de plusieurs opérations arithmétiques. Une opération donnée peut en effet être effectuée simultanément sur plusieurs composantes d’un tableau.
Par exemple, pour effectuer le produit de deux matrices A et B carrées de taille n, on utilise le fragment de code Fortran suivant :
do i = 1, n
do j = 1, n
do k = 1, n
C(i,j) = C(i,j) + A(i,k) * B(k,j)
end do
end do
end do
Le calcul de chaque composante de la matrice C revient à effectuer un produit scalaire d’une ligne de A et d’une colonne de B. Il s’agit donc d’une opération entre vecteurs qui se traduit au niveau de la boucle sur k. On comprend alors l’intérêt de la vectorisation puisque, pour deux indices i et j donnés, les calculs C(i,j) = C(i,j) + A(i,k) * B(k,j) sont indépendants et peuvent donc être réalisés simultanément.
En pratique, les opérations effectuées seront traitées par paquets, c’est-à -dire que le processeur opérera directement sur plusieurs indices simultanément.
La vectorisation est donc une forme particulière de parallélisme qui prend place au sein même des processeurs.
Jeux d’instructions et options de compilations
La vectorisation du code peut se faire grâce aux jeu d’instructions AVX (AVX-512 sur Olympe) : ils permettent une vectorisation sur 512 bits, soit des vecteurs de huit réels en double précision.
Le jeu d’instructions AVX-512 est disponible sur les processeurs Intel Skylake.
La particularité de ces processeurs est de disposer d’une instruction supplémentaire (Fuse Multiple Add, FMA) permettant d’effectuer deux opérations flottantes par cycle supplémentaire par rapport aux processeurs d’anciennes générations.
La vectorisation d’un code peut être prise en compte de manière implicite au moment de la compilation. Pour cela, il faut préciser au compilation le jeu d’instruction qui sera utilisé :
ifort -xCORE-AVX512 monprog.f90
Ainsi, le compilateur générera un binaire adapté au type de processeur et les calculs flottants seront groupés par vecteurs de taille correspondante.
Il est également possible de désactiver de façon explicite la vectorisation du code en remplaçant les balises citées ci-dessus par -no-vec.
Alignement des données en mémoire
Afin d’optimiser un peu plus la mise en place de la vectorisation du code, il est également possible d’aligner les données en mémoire.
En effet, lors d’un calcul, les données sont lues en mémoire par paquets (64 octets sur les architectures actuellement en exploitation).
Si les vecteurs sur lesquels on travaille sont alignés en mémoire sur cette base (i.e. l’adresse mémoire et la taille de ce dernier sont des multiples de 64), alors le transfert de la donnée de la mémoire vers le processeur sera directe. Si les données ne sont pas alignées, un travail supplémentaire devra préalablement être effectué par le processeur, engendrant un temps de calcul supplémentaire.
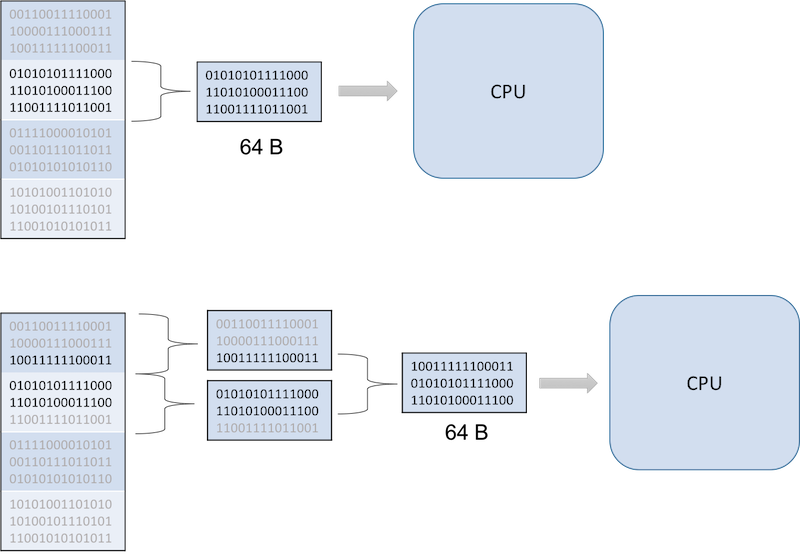
L’alignement des données en mémoire s’effectue de manière implicite par le compilateur dès lors que l’option suivante est ajoutée à la commande de compilation:
-align array64byte
Dans certains cas, par exemple lorsque la taille d’un tableau n’est pas explicitée au moment de la déclaration (allocation dynamique), il peut être nécessaire d’insérer une directive supplémentaire dans le code pour forcer l’alignement en mémoire.
real(kind=8), allocatable, dimension(:,:) :: A real(kind=8), allocatable, dimension(:,:) :: B real(kind=8), allocatable, dimension(:,:) :: C !dir$ attributes align:64 :: A,B,C
Indicateurs de vectorisation du code
Il existe plusieurs moyen d’évaluer le niveau de vectorisation d’un code.
Le premier concerne l’étape de compilation, en utilisation l’option suivante :
-qopt-report=5 -qopt-report-file=fichier.txt
La compilation va alors générer un compte-rendu plus ou moins exhaustif selon la valeur attribuée à qopt-report dans l’option ci-dessus. Ce compte-rendu dresse un bilan de toutes les optimisations effectuées au moment de la compilation, notamment la vectorisation (boucles vectorisées, taille de vecteur, gain estimé ...).
Il est également possible d’obtenir des informations détaillées sur la vectorisation du code en utilisant l’outil Intel Vector Adviser.