VTune [AmplifierXE] est un outil d’analyse de performance de code développé par Intel. Il permet de déterminer facilement les régions chaudes du codes (c’est-à -dire les régions les plus consommatrices en temps de calcul). Il permet de déterminer le profil d’exécution d’un code multithreadé (OpenMP). VTune peut aussi analyser un processus mpi, mais il ne vous dira rien sur les communications inter-nœuds.
Vtune s’utilise en deux étapes :
- ÉTAPE 1: Collection des données sur un nœud de calcul
- ÉTAPE 2: Analyse des résultats à travers une interface graphique :
amplxe-gui
Collecter les données
Le script suivant, utilisé à travers sbatch, permet d’assurer la collecte des données :
#!/bin/bash #SBATCH -J vtune #SBATCH -N 1 #SBATCH -n 36 #SBATCH --ntasks-per-node=36 #SBATCH --ntasks-per-core=1 #SBATCH --time=01:00:00 export OMP_NUM_THREADS=36 module purge module load intel/18.2 module list#vtune-18.2vtune-self-check.shcd ..../bin amplxe-cl -collect hpc-performance ./mon_executable
Les lignes marquées 1 et 2 sont indispensables. Elles vous diront si vous avez les droits suffisants pour utiliser vtune. Si ce n’est pas le cas merci de contacter le support.
Ne pas se noyer sous les données
Évitez de générer de trop gros fichiers ! Il est recommandé de faire vos analyses vtune sur de petits jeux de données, afin d’avoir des temps d’exécution courts et des fichiers de résultats de taille modérée.
Une autre solution est d’arrêter la collecte des données avant la fin de l’application :
- Connectez-vous par ssh sur le nœud de calcul
- Si nécessaire initialisez l’environnement
- Exécutez la commande permettant de stopper la collecte des données : la commande précise est écrite à la fin de votre sortie slurm (fichier
slurm-xxx.out).
Ne pas arrêter vtune avec la commande scancel : cela peut conduire au plantage du nœud de calcul !
Analyser les données
Charger le module intel/18.2 (si ce n’est pas déjà fait), puis lancer l’interface graphique, soit à partir de la frontale soit à partir du nœud graphique
# module load intel/18.2 # amplxe-gui &
Attention : Si vous lancez votre programme à partir de l’interface graphique, il tournera sur la frontale (ou sur le nœud graphique)
Un cas simple:
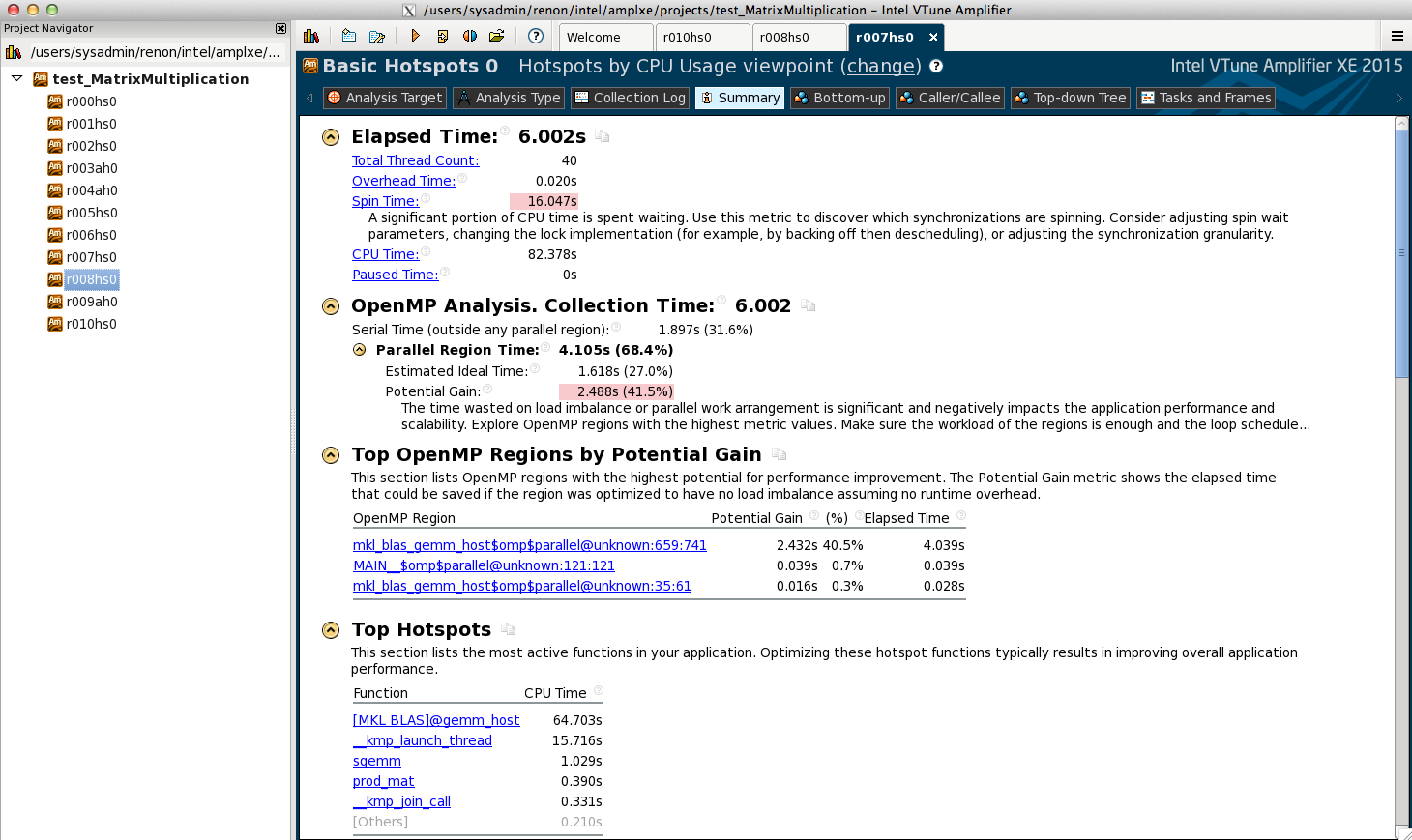
- Le cas étudié est une produit de matrice 2000x2000 en simple précision (SP).
- Le produit est réalisé par appel de la routine BLAS SGEMM de la MKL. Le calcul est multithreadé (-mkl=parallel) sur 20 cœurs physiques.
Ci-dessous les temps d’exécution. La majeure partie du temps est dans SGEMM (ce qui est attendu). Un gain potentiel est indiqué.
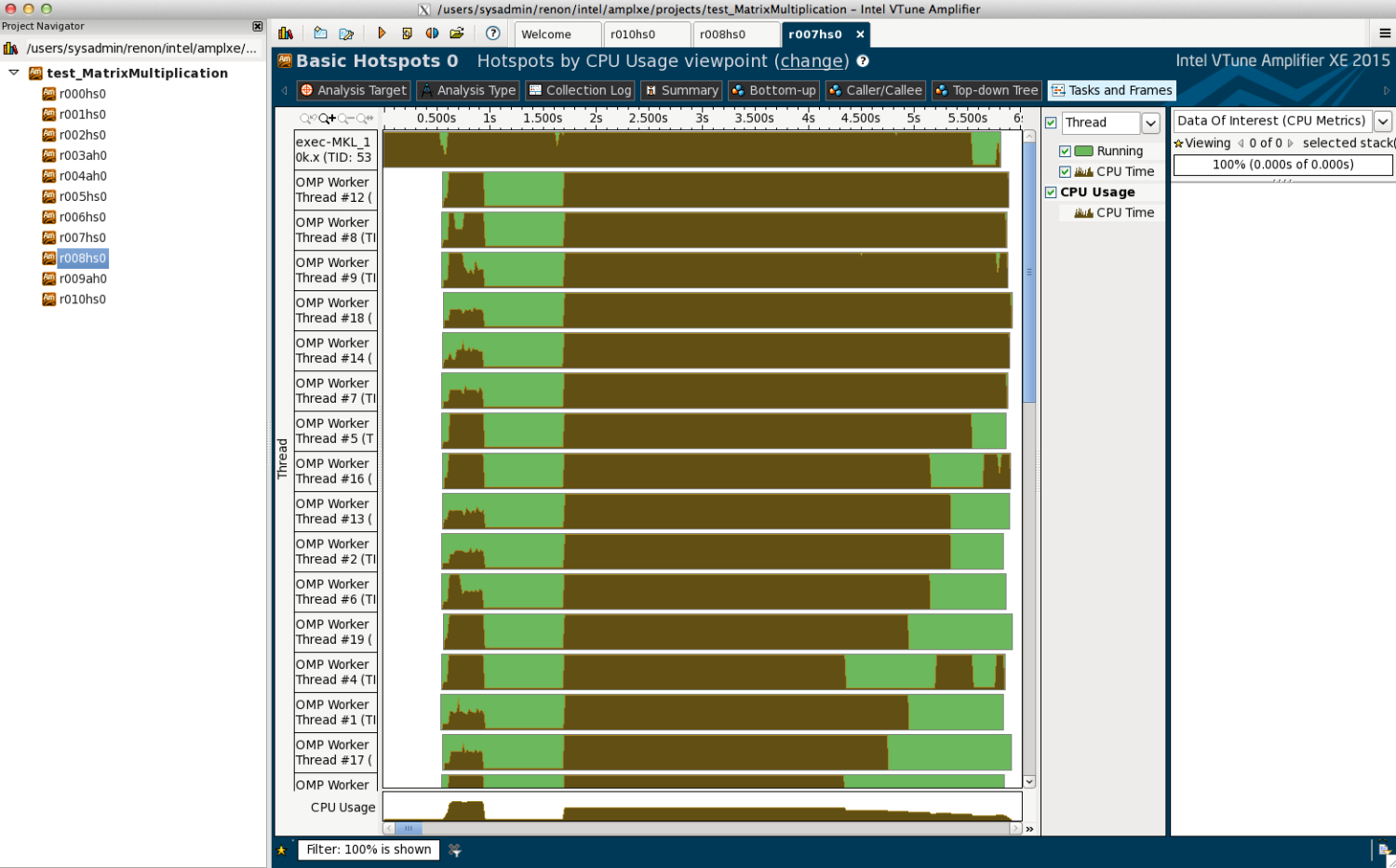
Ci-dessous, on visualise le % d’utilisation du CPU par les 20 threads du calculs.
Ne profiler qu’une partie du code
Afin d’avoir des résultats plus précis, il est souvent nécessaire de ne collecter les données que sur une partie du code : par exemple ne considérer que la boucle principale, en excluant les phases d’initialisation et de terminaison du programme. Pour cela, il est nécessaire d’ajouter dans votre code quelques appels à des fonctions de VTune. En Fortran :
USE ITTNOTIFY ... CALL ITT_PAUSE() ... CALL ITT_RESUME() ... CALL ITT_PAUSE()
Compilation:
Profiler un code MPI avec VTune
Un exemple de script sbatch qui fonctionne avec intelMpi. À adapter pour utiliser openMpi !
#!/bin/bash #SBATCH -J vtune #SBATCH -N 1 #SBATCH -n 36 #SBATCH --ntasks-per-node=36 #SBATCH --ntasks-per-core=1 #SBATCH --time=01:00:00 module purge module load intel/18.2 module list mpiexec.hydra -n 36 -r RESULTATS -gtool "amplxe-cl -collect hpc-performance : 0,1" ./mon_executable
Ligne 1: le paramètre 0,1 correspond aux rangs MPI que l’on souhaite profiler. Il est généralement inutile de profiler tous les processus mpi, puisqu’ils sont censés se comporter tous de la même manière. Le switch -r est indispensable, et les résultats seront déposés dans les répertoires RESULTATS.0 et RESULTATS.1
Attention ! Il s’agit ici de profiler de façon indépendante l’exécution d’un ou plusieurs processus issus d’un programme MPI. Aucune information concernant les communications ne sera collectée, pour cela voir ici