Sur cette page, il est expliqué comment vérifier que le connecteur NVLink est utilisé pour communiquer directement des messages entre les cartes graphiques. Le premier paragraphe explique comment modifier votre script sbatch pour ajouter la lecture des compteurs qui nous indiqueront si NVLink est utilisé. Le deuxième paragraphe explique comment interpréter les résultats, et le troisième paragraphe est un exemple de code utilisant NVLink où l'on peut observer le trafic sur le connecteur.
Lignes sbatch nécessaires pour regarder le trafic NVLink
Dans le script sbatch, après les lignes "SBATCH ...", il faut ajouter la ligne suivante :
#nvprofiling
Attention, le "#" est important !!
On charge le module dcgm:
module load dcgm/2.3.4-1
Ajoutez les lignes suivantes avant la ligne d'exécution (mpirun, srun) pour initialiser dcgmi :
nv-hostengine --pid nvhostengine.pid --log-filename nv-hostengine.log
export UCX_MEMTYPE_CACHE=n
dcgmi dmon -e 1011,1012 -c 2000 > compteur.${SLURM_JOB_ID} &
Après l'exécution, ajoutez cette ligne pour arrêter la lecture des compteurs :
kill -9 $(cat nvhostengine.pid)
Interpretation des résultats
À l'intérieur du répertoire de résultats, par exemple "123234", vous trouverez le fichier "compteurs.123234"
qui vous montrera le trafic entre les cartes. Si vous voyez que des "0", cela signifie qu'il n'y a pas de trafic.
Si NVLink est correctement utilisé, vous verrez que le trafic est différent de "0".
Exemple de code qui utilise le NVLink entre les GPUs
Ici, vous pouvez télécharger ce répertoire "test_nvlink.tar" qui contient tout le nécessaire pour vérifier l'utilisation de NVLink sur Olympe.
Il s'agit d'un code qui effectue un ping-pong entre deux GPU en utilisant NVLink.
Une fois téléchargé sur Olympe, vous décompressez le fichier :
tar xf nvlink_test.tar
Ensuite, lancez le script sbatch :
sbatch run_test_nvlink.sh
L'exécution va générer un répertoire de résultats de la forme "123234", et à l'intérieur, vous pouvez consulter le fichier "compteurs.123234".
Analyse de bande passante entre 2 GPUs à l'interieur du même noeud et 2 GPUs de different noeuds
Comment mettre en place les environnements utilises pour ces analyses est expliqué dans la section suivante.
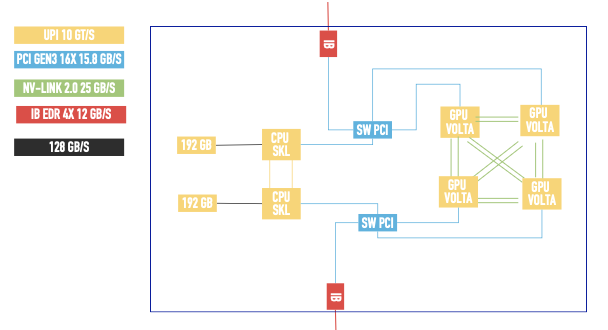
La connectivité à l'intérieur et vers l'extérieur du nœud est la suivante :
Le graphique suivant montre la bande passante obtenue avec plusieurs environnements pour différentes tailles de messages:
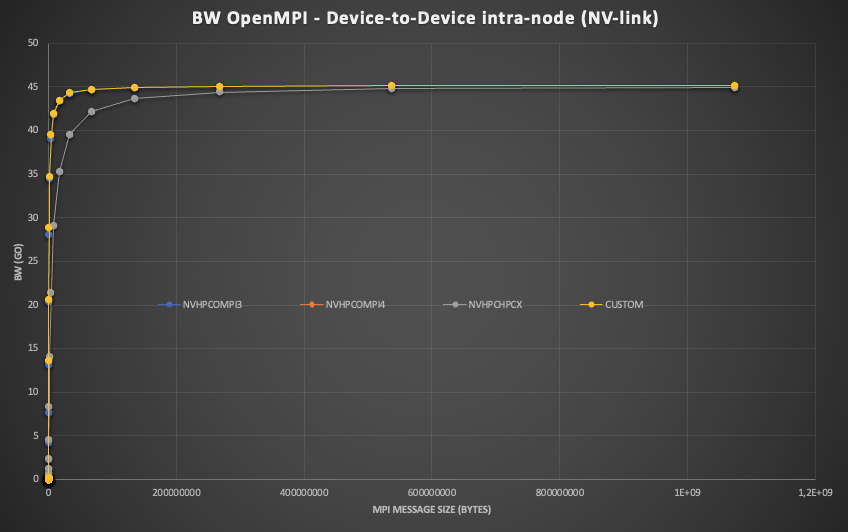
À l'intérieur du nœud, les cartes son sont interconnectées avec deux NV-Link 25 GB/s, ce qui donne un total de 50 GB/s de bande passante.
On observe qu'à partir d'une certaine taille de message (~5 Mo), tous les environnements atteignent presque la limite de bande passante.
Le graphique suivant montre la même analyse que le cas précédent, mais avec 2 GPU situés dans des nœuds différents :
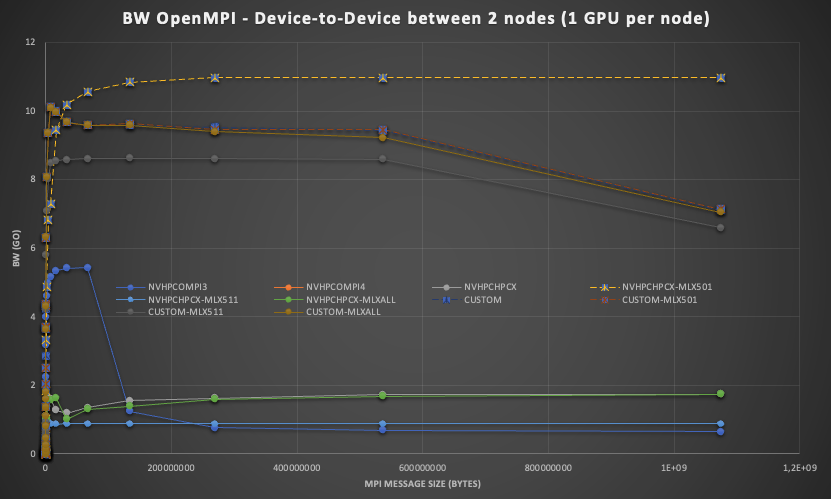
Pour sortir du nœud, la carte est connectée à un switch PCI avec du PCI Gen3 16x 15,8 GB/s, et le switch est connecté à la carte InfiniBand EDR 4x 12 GB/s.
On remarque que l'environnement a un impact significatif, surtout pour les messages de plus de 2 Mo.
Comme nous pouvons l'observer dans l'image de l'architecture du nœud, il y a deux GPUs attachés à un switch et 2 GPUs attachés à l'autre switch.
Plus précisément, les GPUs 0 et 1 sont attachés au switch MLX-501, et les GPUs 2 et 3 sont attachés au MLX-511.
Si dans notre commande mpirun, nous indiquons le switch qui est à côté du GPU, la bande passante est jusqu'à x6 fois plus importante que si rien n'est indiqué, et x12 fois plus que si on explicite d'utiliser le switch distant.
Ce phénomène est très bien visible sur le graphique où les GPUs plus proches du MLX-501 sont utilisés. Regardez la difference entre NVHPCPCX-MLX501 et NVHPCPCX-511.
Environnements qui utilissent le NVLink
module load nvidia/nvhpc/22.1-cuda-11.5-majslurm ulimit -s 10240 export OMPI_MCA_mtl=^mxm export OMPI_MCA_pml=^yalla export OMPI_MCA_mpi_cuda_support=1
Pour l'utiliser dans l'exemple test_nvlink.tar il faut changer aussi le Makefile_ucx:
OMPI_DIR =/usr/local/nvidia_hpc_sdk/MAJSLURM/Linux_x86_64/22.1/comm_libs/mpi
module load nvidia/nvhpc/22.1-cuda-11.5-ompi405-majslurm export UCX_MEMTYPE_CACHE=n
module load nvidia/nvhpc/22.1-cuda-11.5-ompi405-majslurm
export PATH=/usr/local/nvidia_hpc_sdk/MAJSLURM/Linux_x86_64/22.1/comm_libs/hpcx/hpcx-2.10.beta/ompi/bin:${PATH}
export LD_LIBRARY_PATH=/usr/local/nvidia_hpc_sdk/MAJSLURM/Linux_x86_64/22.1/comm_libs/hpcx/hpcx-2.10.beta/ompi/lib:${LD_LIBRARY_PATH}
export UCX_MEMTYPE_CACHE=n
Pour l'utiliser dans l'exemple test_nvlink.tar il faut changer aussi le Makefile_ucx:
OMPI_DIR =/usr/local/nvidia_hpc_sdk/MAJSLURM/Linux_x86_64/22.1/comm_libs/hpcx/hpcx-2.10.beta/ompi
CUSTOM (utilisé dans test_nvlink.tar)
module load openmpi/pgi/4.0.4-UCX-cuda export UCX_MEMTYPE_CACHE=n
OMPI_DIR =/usr/local/openmpi/pgi/openmpi404_pg1910_cuda101105_ucx18_gdrcopy2-maj-scs5-R3
Pour indiquer quelle carte InfiniBande utiliser:
- MLX 501