ATTENTION - Cet article date de 2014, les tests ont été effectués sur Eos (le supercalculateur précédent Olympe). Eos avait 20 cœurs par nœud (40 si on utilisait l'hyperthreading)
Ces tests de passage à l'échelle sont effectuées en mémoire partagée.
Nous traitons ici différents cas, puisque nous faisons varier aussi bien la taille de la matrice carrée (5000, 10000, 25000 et 50000 lignes/colonnes), que le nombre de cœurs sur lequel est lancé ce calcul : 1 cœur (sequentiel), 5 cœurs, 10 cœurs, 20 cœurs, 40 cœurs (utilisation de l'hyperthreading, Eos avait 20 cœurs physiques par nœud).
Dans l’environnement par défaut
Squelette du script testé dans l’environnement par défaut :
#!/bin/bash
#SBATCH -J script_art421
#SBATCH -N 1
#SBATCH -n 1
#SBATCH --threads-per-core=1
#SBATCH --cpus-per-task=5
workdir=${SLURM_SUBMIT_DIR}/JOB_${SLURM_JOBID}
mkdir ${workdir}
cd ${workdir}
cp $0 .
export OMP_NUM_THREADS=$SLURM_CPUS_PER_TASK
MKL_NUM_THREADS=$OMP_NUM_THREADS
srun -N 1 -n 1 -c $OMP_NUM_THREADS ./mon_appli.exe > output_${SLURM_JOBID}.log
On s’intéresse au speed up de ce calcul, à savoir le ratio du temps de calcul en séquentiel (sur 1 cœur) sur le temps de calcul en parallèle sur n cœurs :
Sp=Tséquentiel/Tparallèle
Plus ce ratio se rapproche du nombre de cœurs utilisés pour le calcul parallèle, plus l’efficacité parallèle de ce code est bonne. Par exemple : si avec 10 cœurs on va dix fois plus vite qu’en séquentiel, alors le speed up vaut 10 et il est donc idéal.
Pour l’exemple traité ici, le speed up a été calculé sur la base des temps de restitution ci-dessous :
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
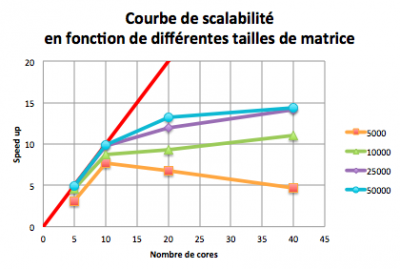
Courbe de scalabilité (ou courbe d’extensibilité) : courbe affichant le speed up en fonction du nombre de cœurs sur lesquels est lancé le calcul
Ci-dessous la courbe de scalabilité associée au code calculant le résultat de la multiplication de deux matrices carrées non vides de différentes tailles (5000, 10000, 25000 et 50000 lignes/colonnes).
On peut voir que pour 5 cœurs (respectivement 10 cœurs), quelque soit la taille du problème, le speed up est très bon puisqu’il est très proche de 5 (respectivement 10).
Par contre pour le problème de taille 5000, augmenter encore le nombre de cœurs dégrade le speed up. La scalabilité dépend donc de la taille du problème étudié.
En initialisant la variable : OMP_PROC_BIND=true
Cette variable assure que lorsqu’une tâche est lancée sur un cpu, elle reste bien sur celui-ci. De plus, elle répartie les tâches uniquement sur les cœurs physiques, et dans l’ordre. Ainsi pour un nombre de tâches égal à 10, les threads occuperont les cœurs de 0 à 9.
Les temps de restitution que nous obtenons alors sont les suivants :
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Pour le problème de petite taille (n=m=5000), les temps de restitutions sont très faibles (<2s) et varient d’un job à un autre, ce qui empêche de tirer une conclusion claire.
Pour les problèmes de plus grande taille (n=m=25000 et 50000), on voit que lorsqu’on utilise moins de la moitié du nœud (nombre de cœurs < ou = à 10), sans spécifier de placement particulier, les tâches se répartissent "naturellement" sur des cœurs différents. Lorsqu’on les place avec l’option OMP_PROC_BIND, cette répartition est plus "propre", mais ne change pas les temps de calcul.
Par contre lorsqu’on utilise la totalité du nœud sans spécifier de placement, certaines tâches vont se placer sur des cœurs physiques et leur cœurs logique associé, créant de l’hyperthreading. Avec l’option OMP_PROC_BIND toutes les tâches sont placées sur les cœurs physiques, on gagne systématiquement 30% de temps de calcul (pour cet exemple) et on améliore grandement le speed up. Pour les problèmes de grande taille, il est presque idéal : lorsqu’on fait tourner un job sur x cœurs, il va x fois plus vite qu’en séquentiel (sauf si on utilise l' hyperthreading).
| Taille de la matrice | ||||
|---|---|---|---|---|
| Cœurs | 5000 | 10000 | 25000 | 50000 |
| 1 | - | - | - | - |
| 5 | 3,33 | 4,80 | 4,93 | 4,96 |
| 10 | 4.57 | 8,69 | 9,76 | 9,94 |
| 20 | 7,51 | 13,49 | 19,10 | 19,56 |
| 40 | 8,36 | 11,40 | 11,62 | 11,09 |
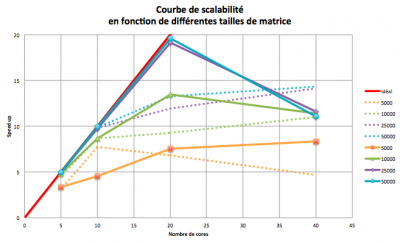
- En pointillés : speed up précédent
- En traits pleins : speed up avec la variable
OMP_PROC_BIND=true - 40 cœurs, soit 20 cœurs physiques + 20 cœurs logiques (hyperthreadés)