In ParaView, the prefix "Para" stands for "parallel" : How can we activate parallelism in ParaView ?
How to use this tutorial
- This tutorial was only tested with the release 5.5.2 of ParaView
- If you have data to be visualized by ParaView, you can use your data.
- If you don’t have data yet, you can use some little scripts [37] written in python :
- first, copy the scripts to your personal disk space
- Start paraview (see under)
- you can read one script with the menu item :
View/Python shell/Run script
module load paraview/5.5.2 cp -r $PARAVIEW_ROOT/examples/python-scripts .
Starting a graphics session
ParaView must be used from a graphics session. Because we want to visualize very big datasets, we probably need more memory than the default. We must also specify that we want more than 1 core.
The complete story is here. You can use the following command to start a graphics session:
runVisuSession.sh --cpus-per-task 4 --mem 40G
Starting a visualization server
The ParaView gui cannot use several cores. Only the readers and the visualization engines can use several cores. So we must start a server process, using mpi to make it to work in parallel. As we have 4 cores in this session, let’s dedicate 3 of them to the server, keeping 1 core for the gui.
Open a terminal and type the following :
$ mpirun -np 3 pvserver --disable-xdisplay-test Waiting for client... Connection URL: cs://olympevolta11.bullx:11111 Accepting connection(s): olympevolta.bullx11:11111
Starting the ParaView gui
Start ParaView version 5.5.2, using the main graphics menu : put the mouse over the root window, click with the right button, and choose the item:
Visualization_Applications/Paraview
Configuring the connection
The procedure described here should be done only the first time : the configured connection(s) will be kept from session to session.
- When Paraview is started, click on the menu item :
File/connect - A window entitled
Choose Server Configurationopens, click the buttonAdd Server - A window entitled
Edit Server Configurationopens with several fields, all fields being already filled. Modify the value of the field Name, writing the name you choose for the connection : saymy_pvserver, then click the buttonConfigure - A window entitled
Edit Server Launch Configurationopens, just click the buttonSave
Connecting to the pvserver
If not already done, start Paraview and click the menu item : File/connect, then select the my_pvserver line and click the Connect button. You are now connected to the pvserver, as indicated in the Pipeline browser window (see figure)
Besides, if you look at the window from which you launched pwserver, you should see this message :
Client connected
Loading and displaying data
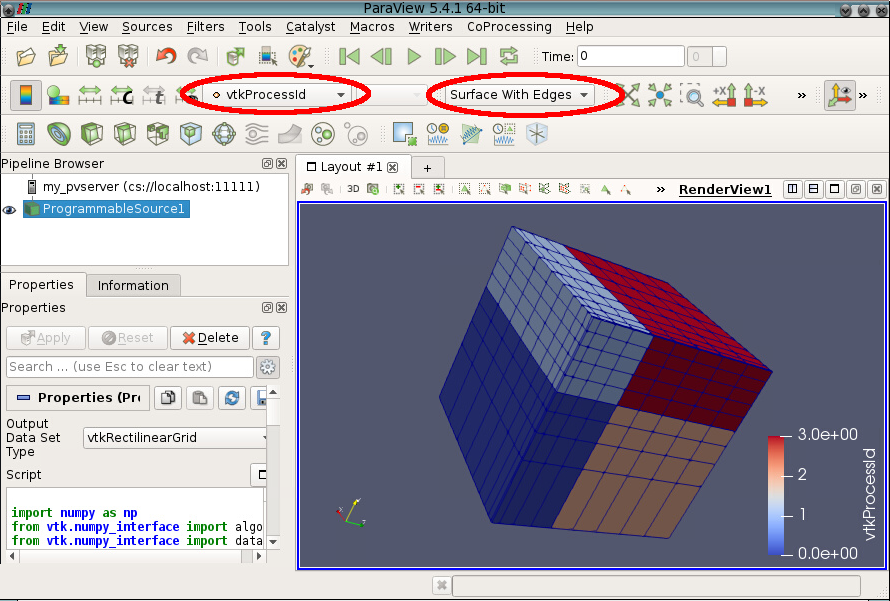
- Figure obtained with 4 processors, using the python script rectilinear.py
You can now load your datafiles, your state files, your python scripts, exactly as usual.
Warning : to read a python script, you must use the menu item : View/Python shell/Run script.
Data will be read by pvserver, and rended and displayed by ParaView. You should have a new property available with your data : vtkProcessId
You can easily display the domain decomposition made pvserver for reading your data (see the figure).
If you execute a filter, it will be executed by pvserver, thus using several cores, which can lead to faster execution if you have a huge quantity of data to treat
(1) We thank M. Jean Favre, from CSCS, who authorized us to share those scripts