Dans cette page :
How to use this tutorial ?
Each entry point of the tutorial is dedicated to a usecase, from the most general and simple to the most specific and complicated. To understand what happens when chdb is launched for a real problem we’ll use some very simple bash commands. You should :
- read carefully the few lines before and after each code sample, to understand the point.
- copy-and-paste each code sample provided here, execute it from the frontal node, and look at the created files using the unix standard tools as find, ls, less, etc.
Of course, in the real life, you’ll have to replace the toy command line launched by chdb by your code, and yo must launch chdb through an sbatch command, as usual. Please remember you cannot use the frontal nodes to launch real applications, the frontal nodes are dedicated to file edition or test runs.
Also in the real life, you should use srun to launch chdb program, not mpirun. Use mpirun to stay on the frontal, and srun to go to the nodes.
Introduction
Before starting...
You should be connected to Olympe before working on this tutorial. You must initialize your environment to be able to use the commands described here :
module load intelmpi chdb/1.0
You should work in an empty temporary directory, to be sure you’ll not remove important files while executing the exercises described in the following paragraphs :
mkdir TUTO-CHDB cd TUTO-CHDB
Help !
You can ask chdb for help :
chdb --help
Essential
- Executing the same code on several input files
- How many processes for a chdb job ?
- specifying the output directory
- Executing your code on a subset of files
- Executing your code on a hierarchy of files
- Managing the errors
Executing the same code on several input files
How many processes for a chdb job ?
specifying the output directory
If you do not provide chdb with any output specification, chdb will build an output directory name for you. But of course it is possible to change this behaviour. This is particularly useful when using chdb through slurm (which is the standard way of working), as you can integrate the job Id in the output directory name :
salloc -N 1 -n 36 --time=2:0; mpirun -n 2 chdb --in-dir inp --in-type txt \ --command-line 'cat %in-dir%/%path% >%out-dir%/%basename%.out' \ --out-dir $SLURM_JOB_ID exit
Executing your code on a subset of files
Executing your code on a hierarchy of files
Managing the errors
The default behaviour of chdb is to stop as soon as an error is encountered, as shown here : we create 10 files, artificially provoke an error on two files, and run chdb :
rm -r inp inp.out; mkdir inp; for i in $(seq 1 10); do echo "coucou $i" > inp/$i.txt; done chmod u-r inp/2.txt inp/3.txt mpirun -n 2 chdb --in-dir inp --in-type txt \ --command-line 'cat %in-dir%/%path% >%out-dir%/%basename%.out \ 2>%out-dir%/%basename%.err' find inp.out
chdb writes an error message on the standard error, and stops working : very few output files are indeed created. We know that the problem arose in file 2.txt, so it is easy to investigate :
ERROR with external command - sts=1 input file=2.txt ABORTING - Try again with --on-error find inp.out cat inp.out/2.err
Thanks to this behaviour, you’ll avoid wasting a lot of cpu time just because you had a error in some parameter. However, please note that in the following exercise the file 3.txt has the same error, but as chdb stopped before running processing this file, you are not aware of this situation. You can modify this behaviour :
rm -r inp inp.out; mkdir inp; for i in $(seq 1 10); do echo "coucou $i" > inp/$i.txt; done chmod u-r inp/2.txt inp/3.txt mpirun -n 2 chdb --in-dir inp --in-type txt \ --command-line 'cat %in-dir%/%path% >%out-dir%/%basename%.out \ 2>%out-dir%/%basename%.err' \ --on-error errors.txt find inp.out
Now all files were processed, and a file called errors.txt is created : the files for which your program returned a code different from 0 (thus considered as an error) are cited in the output file errors.txt. It is thus simple to know exactly what files were not processed, and for what reason (if the error code returned by your code is meaningful). When the problem is corrected, you’ll be able to run chdb again using only those files on input.
for more clarity we changed the file name of errors.txt to input_files.txt, but this is not required :
chmod u+r inp/2.txt inp/3.txt mv errors.txt input_files.txt mpirun -n 2 chdb --in-dir inp --in-type txt \ --command-line 'cat %in-dir%/%path% >%out-dir%/%basename%.out \ 2>%out-dir%/%basename%.err' \ --on-error errors-1.txt \ --out-dir inp.out-1 \ --in-files input_files.txt
Advanced
- Generating an execution report
- Improving the load balancing (1/2)
- Improving the load balancing (2/2) :
- Avoiding Input-output saturation
- Launching an mpi program
- Controlling the placement of an mpi code
Generating an execution report
Improving the load balancing (1/2)
Improving the load balancing (2/2) :
Avoiding Input-output saturation
While having different run times for the many code instances you launch may cause a performance issue (see above), launching a code which lasts always the same time may also be a problem : Real codes, when running, frequently need to read or write huge datafiles, generally at the beginning of the job and at the end (and sometimes during the job, between iterations). If you launch simultaneously 10 such codes with chdb, the file system may be rapidly completely saturated, because all the jobs will try to read or write data synchronously. chdb allows for you desynchronizing the jobs, as shown under :
Launching an mpi program
The code you want to launch through chdb does not have to be sequential : it can be an mpi-base program. In this case you must tell this to chdb.
To go on with the tutorial, please download this toy program. This code :
- Prints the chdb slave number and the mpi rank number
- Is linked to the numa library, to print the cores that could be used by each mpi process
(if you do not understand the C code of hell-mpi.c this is not a problem, it is not needed to go on with this tutorial).
We rename the downloaded file and compile the program :
mv hello-mpi.c.txt hello-mpi.c mpicc -o hello-mpi hello-mpi.c -lnuma
Now, let’s run our mpi code through chdb : for this exercise we use srun, in order to leave the front node and work on a compute node. We have 10 input files, and our slave needs 2 mpi processes to run. This makes sense reserving a complete node, starting 19 mpi processes :
rm -r inp inp.out; mkdir inp; for i in $(seq 1 18); do echo "coucou $i" > inp/$i.txt; done srun -N 1 -n 19 chdb --in-dir inp --in-type txt \ --command-line './hello-mpi %name%' \ --mpi-slaves 2
The switch —mpi-slaves tells chdb that the external code is an mpi program, and the number of processes to launch. Here is the output :
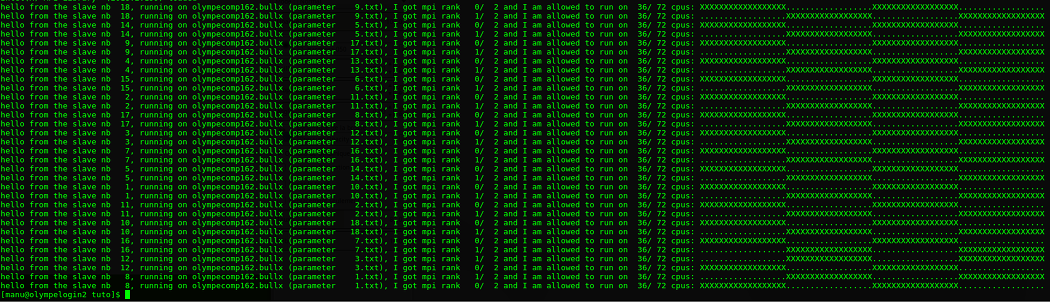
Controlling the placement of an mpi code
If you look at the output above, you’ll see that if several mpi processes belonging to the same slave do not overlap (they use different core sets), there is a huge overlap between different chdb slaves. This can be avoided, slightly modifying the chdb command.
Here with decided to start a run with the following characteristics:
- 18 slaves running on only one node
- Each slave is an mpi program using 2 processes
- Each process uses only 1 thread (no openmp)
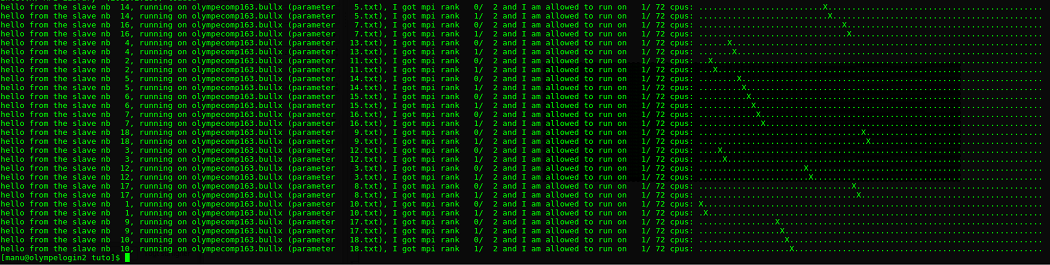
rm -r inp.out srun -N 1 -n 19 chdb --in-dir inp --in-type txt \ --command-line './hello-mpi %name%' \ --mpi-slaves 18:2:1
The important switch is --mpi-slaves 18:2:1, telling chdb that :
- We are running 18 slaves per node
- Each slave is an mpi code using 2 mpi processes
- Each mpi process uses 1 thread
Here is the output, this time there is no overlap between slaves :
Another use case: let's launch a run using 2 nodes, 4 slaves per node (thus 2x4 + 1 = 9 chdb tasks), 4 mpi processes per slave and 2 threads per mpi process. The command becomes:
srun -N 2 -n 9 chdb ... --mpi-slaves 4:4:2
Miscellaneous
- Working with directories as input
- Executing a code a predefined number of times
- Checkpointing chdb
- Controling the code environment (v 1.1.x)
Working with directories as input
Many scientific codes prefer to work inside a current directory, reading and writing files in this directory, sometimes hardcoding file names.
Executing a code a predefined number of times
chdb can be used to execute a code a predefined number of times, without specifying any file or directory input :
rm -r iter.out mpirun -n 3 chdb --out-dir iter.out \ --command-line 'echo %path% >%out-dir%/%path%' \ --in-type "1 10"
It is not required specifying an output directory, as shown here :
rm -r iter.out mpirun -n 3 chdb \ --in-type "1 20 2" \ --command-line 'echo slave nb $CHDB_RANK iteration nb %path%'
The environment variables and the file specification templates are still available in this mode of operation.
Checkpointing chdb
WARNING - The feature described here is still considered as EXPERIMENTAL - Feedbacks are welcome
If chdb receives a SIGTERM or a SIGKILL signals (for instance if you scancel your running job), the signal is intercepted, and the input files or iterations not yet processed are saved to a file called CHDB-INTERRUPTION.txt. The files being processed when the signal are received are considered as "not processed", because the processing will be interrupted.
It is then easy to launch chdb again, using CHDB-INTERRUPTION.txt as input.
Let’s try it using in-type iteration for more simplicity :
rm -rf iter.out iter1.out mpirun -n 3 chdb --out-dir iter.out --in-type "1 100" \ --command-line 'sleep 1;echo %path% >%out-dir%/%path%'
Execute the above commands, wait about 10 seconds, then type CTRL-C. The program is interrupted, CHDB-INTERRUPTION.txt is created.
First have a look to CHDB-INTERRUPTION.txt, check the last line :
# Number of files not yet processed = 56
If this line is not present, the CHDB-INTERRUPTION.txt is not complete and it can be difficult to resume the execution of your job.
If CHDB-INTERRUPTION.txt is complete, we can launch chdb again using the --in-files switch, and this time we wait until the end :
mpirun -n 3 chdb --out-dir iter1.out --in-type "1 100" \ --command-line 'sleep 1;echo %path% >%out-dir%/%path%' \ --in-files CHDB-INTERRUPTION.txt
You can now check that every file was correctly created ; the following command should display 100 :
find iter.out iter1.out -type f| wc -l
Controling the code environment (v 1.1.x)
STILL BUILDING - DOES NOT WORK YET !
WARNING - for using this feature, please initialize the chdb environment with:
module load chdb/1.1.0
Starting with the 1.1.0 release, there is a better isolation between an mpi code executed by the chdb slaves and the chdb code himself. This is an important feature, because at Calmip we provide several flavours of the mpi library: different versions of intelmpi and different versions of openmpi.
You can completely control your program environment, regardless of the chdb environment. This paragraph explains how.
Controlling the mpi flavour:
export CHDB_MPI=openmpi
or
export CHDB_MPI=intelmpi
Declaring modules:
Suppose your code needs the modules: openmpi/gnu/2.0.2.10, gcc/5.4.0, and hdf5/1.10.2-openmpi:
export CHDB_MODULES="openmpi/gnu/2.0.2.10 gcc/5.4.0 hdf5/1.10.2-openmpi"
(the separator is: <space>)
Defining environment variables:
You can define environment variables for your code in two ways:
Giving only the name of the variables:
In this way, the environment variables should be already defined, you just have to cite their names:
export CHDB_ENVIRONMENT="OMP_NUMTHREADS OMP_PROC_BIN"
Defining the variable name and value:
In this way, the variable does not need to be already defined, you just have to define the name=value in one shot:
export CHDB_EXPORT_LIST="MY_VAR1=4 MY_VAR2=5"
Declaring code snippets:
May be you have to execution some unix commands commands before running your code. It is possible to introduce some bash fragments:
export CHDB_SNIPPET='ulimit -s 10240; source my_code_init.bash'
With those environment variables, chdb is able to "write" some script, with some instructions called just before running your code. And the environment used by chdb itself (ie gcc 10.3.0 and intelmpi) is completely forgotten when your code is running