ATTENTION - Cet article fait référence à Eos, le supercalculateur précédent Olympe
Dans cet article, on propose une évaluation des gains potentiels liés à la vectorisation d’un code.
On utilise pour cela un code Fortran 90 qui effectue le produit de deux matrices en Double Précision. vous pouvez le télécharger ici
On s’intéresse ici aux jeux d’instructions AVX (processeurs Ivybridge d’EOS) et AVX2 (processeurs Haswell du noeud MESCA).
| Machine | à partir processeur | Instruction | opération | Taille des vecteurs |
| EOS | Ivydridge | AVX | mult ou add | 256 bit |
| MESCA | Haswell | AVX2 | Fuse Multiple-Add | 256 bit |
Les options de compilation à utiliser pour ces jeux d’instructions sont les suivantes. On peut aussi désactiver la vectorisation avec l’option -no-vec.
Le code est purement séquentiel. Cependant deux types de calculs ont été effectués :
- des exécutions purement séquentielles, on utilise un seul core du processeur,
- des tests de charge, on lance autant d’instances du calcul séquentiel qu’il y a de cores au sein du processeur (i.e. sur EOS : 10 cores, processeurs Ivybridge (AVX) ; sur MESCA : 16 cores, processeurs Haswell (AVX2)).
Les calculs sont exécutés en batch sur EOS et MESCA au travers des scripts de soumission présentés.
 |
|
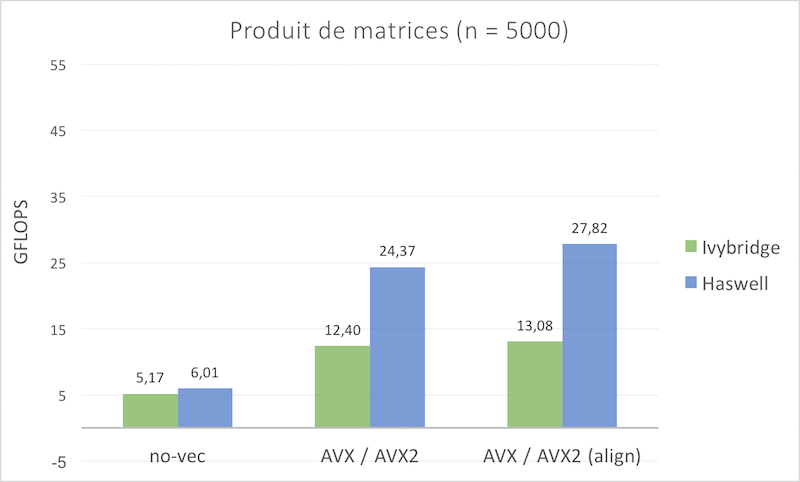
- Les résultats sont exprimés en GFLOPS (milliards d’opérations flottantes par seconde), i.e. le rapport entre le nombre total d’opérations effectuées et le temps de calcul. Plus cette valeur est élevée, plus le temps de restitution est court.
- Les instructions
#SBATCH -c 20et$(placement 1 20)servent à s’assurer que l’on a bien réservé un nœud complet sur EOS (ou un socket complet sur MESCA), le calcul restant quant à lui bien monoprocesseur.
- Pour les jeux d’instruction AVX et AVX2, on considère les cas de données alignées en mémoire (
!dir$ attributes align:64 :: a,b,c) ou non.
Conclusion :
L’utilisation de la vectorisation permet de doubler la puissance de calcul par rapport à la version non vectorisée.
Aussi, l’utilisation du jeu d’instruction AVX2 permet de gagner un facteur supplémentaire sur la puissance de calcul restituée.
Remarque :
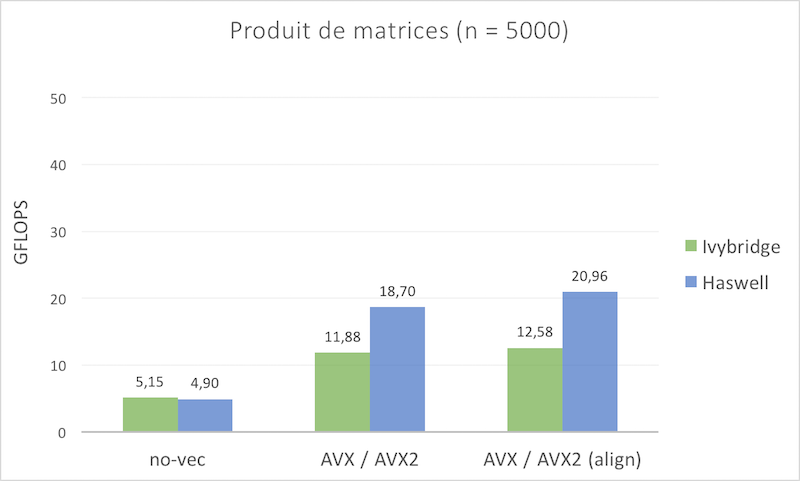
Il y a cependant un biais dans cette étude : la taille des mémoires caches (25 MB par socket de 10 cores sur EOS et 40 MB par socket de 16 cores sue MESCA).
Afin d’imposer un équilibre, on propose de charger les processeurs de la faà§on suivante :
- sur un noeud d’EOS (20 cores), on lance 20 processus (identiques et indépendants). En moyenne chacun disposera donc de 2,5 MB de mémoire cache ((25MB x 2 sockets) / 20 cores).
- sur MESCA on lance 16 processus sur un socket. En moyenne, chacun disposera aussi de 2,5 MB de cache (40 MB x 1 socket / 16 cores).
 |
|
Cette fois-ci, l’architecture Haswell perd l’avantage de sa mémoire cache plus importante. Dans le cas purement scalaire (pas de vectorisation ni de FMA), la puissance de calcul de ces processeurs ne dépasse plus celle des processeurs Ivybridge.